見ヨウ見マネ

今回は日本語・英語のサイトを探して記事を拝見し、見よう見まねで『この画像は○○だろう』という推論のプログラムを使ってみました。
サンプルで画像表示

ユーザーガイドを参照すると、8ページに”Sample Applications”という項がありJetpakに含まれるサンプルアプリが紹介されています。
これらは画面左上のファイルアイコン(ファイルマネジャ)を開き、左側にあるメニューの”Othe Location”をクリックすると出てくる”Computer”というドライブアイコンをクリックすると表示できます。
例えば”CUDA”であれば、先ほど開いた “Computer” ドライブの中の “usr”⇒ “local” と進むと下表の名を冠したフォルダが現れます。
| JetPack component | Sample locations on reference filesystem |
| TensorRT | /usr/src/tensorrt/samples/ |
| cuDNN | /usr/src/cudnn_samples_/ |
| CUDA | /usr/local/cuda-/samples/ |
| Multimedia API | /usr/src/tegra_multimedia_api/ |
| VisionWorks | /usr/share/visionworks/sources/samples/ /usr/share/visionworks-tracking/sources/samples/ /usr/share/visionworks-sfm/sources/samples/ |
| OpenCV | /usr/share/OpenCV/samples/ |
| VPI | /opt/nvidia/vpi/vpi-0.0/samples |
その”CUDA”でサンプル画像を表示するソースを実行してみます。
ファイルマネジャーから “Computer” ⇒ “usr” ⇒ “local”⇒ “cuda10.2” ⇒ “samples” ⇒ “5_simulations”⇒ “oceanFFT”と進みます。この状態でフォルダ内で右クリックし “Open in Terminal”を選択してterminalを開きます。
開いたterminalでは下図のような表記になっていると思います。
| /usr/local/cuda-10.2/samples/5_simulations/oceanFFT $ |
ここで “sudo make”を実行します。コンピューターのパスワード入力が求められると思います。そのまま進みます。
makeコマンドとは、アプリをコンパイルする、実行するといったものです。
| $ sudo make |
次に入力を求められたら “ls”(エルエス)と入力します。lsコマンドは一覧表示する指示です。
| $ ls |
おそらく “oceanFFT”という文字が緑色で表示されていると思います。これを実行してみます。
| $ ./oceanFFT |
何か青っぽい画像が表示されると思います。これでサンプルは終了です。
画像を試しに扱うことができたと思います。ネット上の先人たちのサンプルコードではVisionWorksやOpenCVもよく使われているので、参考にされると良いと思います。
NVIDIA: JETSON NANO DEVELOPER KIT User Guide
デジタルライト: 第2回ゼロから始めるJetson nano : とりあえずデモを動かす方法
画像推論の環境整備
環境の準備

まず、Jetsonの最初の準備で”JetPack”はインストールしたので次へ。
GitHubというサイトから、”Hello AI World”のソース一式を取得する必要があるという事で、以下のコードを実行。
”sudo”なのでパスワードを求められました。
| $ sudo apt-get install git cmake |
続けて、今のフォルダ内(カレントディレクトリ)の下の”jetson-inference”にソースを展開します。
| $ git clone https://github.com/dusty-nv/jetson-inference $ cd jetson-inference $ git submodule update –init |
このとき、”jetson-inference”のフォルダが既に作られていると、一行目の”git clone”が実行できません(でした)。
エラーが出ているときは、画面左上のアイコンからファイルアイコンを選び、そこから”jetson-inference”を右クリックしてゴミ箱へ送ります(送りましたら上手くいきました)。
次はPython3(パイソン3)をインストールします。
| $ sudo apt-get install libpython3-dev python3-numpy |
| $ mkdir build $ cd build $ cmake ../ |
ここでインストールするネットワークの種類を選択する画面が出れば正常に進んでいます。
- Image Recognition – all models
- Alexnet
- GoogleNet
- GoogleNet – 12
- ResNet – 18
- ResNet – 50
- ResNet – 101
- ResNet – 152
- VGG – 16
- VGG – 19 デフォルトで3番のGoogleNetと5番のResNet-18が選択されています。そのままでも問題ないですし、全部選択しても問題無いです。 この選択をすると、次にPyTorchのインストールの確認画面が現れます。複数のバージョンが表示された場合、PyThonのバージョンに合わせて選択し、チェックが入った事を確認して次に進みます。
| $ make |
| $ sudo make install |
ここでインストールするネットワークの種類を選択する画面が出れば正常に進んでいます。
Jetsonで画像推論【静止画】
imagenet-consoleで画像を推定

画面左上のファイルアイコンを開き、”Home”にある”jetson-inference”を開きます。続けて、”build”⇒”aarch64″⇒”bin”と順番にフォルダを開いていきます。
最後にフォルダの適当な位置で右クリックをして、ターミナル(端末)で開くを選択します。
開いたTerminalで下記を実行します。
| $ ./imagenet-console –network=googlenet ./images/banana_0.jpg output_0.jpg |
長いときもあれば、短いときもありますが、推定した結果が画像データ(output_0.jpg)としてフォルダに保存されます。
提供した画像データの左上に何パーセントの確率で何だと推定したかが出てきます。
バナナの画像を使うと90%以上の確率でbananaだと返してきました。
ミカンを使った場合、1回目だけ低い確率でトーテムポールと返してきました。その後はorangeと返してきました。
手元にあった救急車の画像を使ったときは、40数%の確率で救急車と返してきました。
| $ ./imagenet-console –network=resnet18 ./images/banana_0.jpg output_1.jpg |
| $ ./imagenet-console –network=resnet50 ./images/banana_0.jpg output_2.jpg |
上記のように”network”の接続先を変更することで、返される推論も変わります。
バナナの画像を送った結果ですが、googlenetが99.90%、resnet-18が99.32%、resnet-50が99.95%の確率でバナナだと回答しました。

実験的にいくつかの画像を比較してみました。
左側の写真がサンプルとして提供した画像、右側の最上段は画像の名称や意図、2段目がGoogleNetでの結果、3段目がResNet-18での結果、最下段がResNet-50での結果です。

| 花瓶に入った花(カサブランカ) |
| 42.53% handkerchief, hankie, hanky, hankey |
| 23.52% handkerchief, hankie, hanky, hankey |
| 34.20% pot, flower pot |
まずは一般的な物として花瓶に入った花を検出・推論しました。
柄が派手なためかハンカチと認識されてしまいました。ResNet-50だけは花瓶と推論しました。

| ネコ(マンチカン)、アップ |
| 24.73% tabby, tabby cat |
| 10.74% Boston bull, Boston terrier |
| 41.33% tabby, tabby cat |

| ネコ(スコティッシュフォールド)、引き |
| 39.43% Persian cat |
| 50.39% Pekinese, Pekingese, Peke |
| 83.20% Persian cat |

| 2匹のネコ、ソファなど雑然とした背景 |
| 22.12% Siberian husky |
| 12.52% black-footed ferret, Mustela nigripes |
| 79.54% Old English sheepdog, bobtail |
猫の画像を3種類与えてみました。
1枚目は”tabby cat”は虎猫やブチネコなどと訳せると思いますので、だいたい当たっていると思います。ボストンテリアは犬なので、これは大ハズレです。
2枚目は”cat”や”Scottish Fold”が正解です。ペルシャ猫は遠からずですが、ペキニーズはだいぶ雰囲気が違います。
3枚目は犬やイタチと推論が出ていました。ResNet-50が示したオールド・イングリッシュ・シープドッグは約80%の確率で示されましたが、だいぶ離れているようにも思えます。
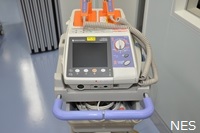
| 除細動器 |
| 23.06% cash machine, cash dispenser, automated teller machine, automaticteller machine, automated teller, automatic teller, ATM |
| 3.96% stretcher |
| 24.46% cash machine, cash dispenser, automated teller machine, automaticteller machine, automated teller, automatic teller, ATM |
除細動器は医療機器なので、教師データが少ないせいかATMなどの現金自動預け払い機と判断されました。ResNet-18ではストレッチャーと推論したので、医療現場という雰囲気が伝わったのかもしれません。

| 自動車、ミニバン |
| 25.37% tow truck, tow car wreker |
| 26.88% convertible |
| 25.05% minivan |

| 救急車(日本仕様) |
| 68.90% ambulance |
| 58.30% ambulance |
| 76.07% ambulance |

| 船、警察船(兵庫県警) |
| 29.32% fireboat |
| 12.01% dock, dockage, docking facility |
| 34.72% speedboat |
乗り物を3点提供したところ、GoogleNetはレッカー車(tow truck)と推定、ResNet-18はオープンカー(convertible)と推定、ResNet-50ではミニバンと推定されました。
2枚目はいずれも救急車と推定されましたが、確率にはバラツキがありました。救急車は国ごとに仕様が異なりますので日本式の救急車を推定できたのは良かったと思います。
船の画像は”fireboat”や”speedboat”はだいたい適当な推定ですが、”dock”はおそらく背景を読み取ったのではないかと思います。

| トイレ、便器(洋式) |
| 74.37% toilet seat |
| 73.83% toilet seat |
| 98.14% toilet seat |

| トイレ、便器(和式) |
| 13.32% crutch |
| 5.75% seat belt, seatbelt |
| 17.86% mousetrap |
次の画像は洋式便器と和式便器を画像認識してみました。
洋式トイレは正答でしたが、確率にはだいぶ差が出ています。
和式トイレは正答できませんでした。”crutch”は松葉杖です。恐らく右上の子供用シートのT型の部分を読み取ったのかなと思います。”seatbelt”も同じだと思います。”mousetrap”はネズミ捕りです。なるほどと思いました。
detectnet-consoleで静止画推論
前述のimagenet-consoleと同じ “~/jetson-inference/build/aarch64/bin/”フォルダにて以下のソースを実行すると画像の推論結果が返されます。
| $ ./detectnet-console ./images/dog_5.jpg output_dog5.jpg coco-dog |
構成は “detectnet-console”のあとに入力画像ファイル名(拡張子付き)、出力画像ファイル名(拡張子付き)、利用モデルの順に並んでいます。モデルには以下のような例があります。
| coco-airplane | airplanes | 飛行機 |
| coco-bottle | bottles | ボトル |
| coco-chair | chairs | 椅子 |
| coco-dog | dogs | 犬 |
| pednet | pedestrians | 歩行者 |
| multiped | pedstrians, luggege | 歩行者、荷物 |
| facenet | feces | 顔 |
実際にプリインストールされていた歩道の犬の映像(静止画)を推論させると下図のような結果が返ります。
手前の犬は99.8%、自転車は85.5%、奥の人々は80%台で認識されています。

Jetsonで画像推論【リアルタイム動画】
カメラを搭載

Jetson Nanoにラズパイカメラ、あるいはUSBカメラを搭載します。
その後、カメラを使ったリアルタイム画像認識・推論を実行します。
ここでも、前述の静止画と同様の記事を参照します。
カメラが正しく動いているかどうかを確認するソースはいくつかありますので以下にリストしておきます。
カメラが取付けられているかどうか、いつ取付けられたのかといったことがわかるソースです。
| $ ls -al /dev/video0 |
カメラの画像を画面表示させるためのソースです。止め方は、キーボードの”q”を押せばQuit指示になります。
| $ nvgstcapture |
次のソースも似たようなものです。
何が起きているかを可視化できるので、少し勉強が進むと理解が深まります。
| $ git clone https://github.com/JetsonHacksNano/CSI-Camera.git |
| $ cd CSI-Camera/ $ ls |
| $ gst-launch-1.0 nvarguscamerasrc sensor_id=0 ! \ ‘video/x-raw(memory:NVMM),width=3280, height=2464, framerate=21/1, format=NV12’ ! \ nvvidconv flip-method=0 ! ‘video/x-raw,width=960, height=720’ ! \ nvvidconv ! nvegltransform ! nveglglessink -e |
カメラ画像を消すには、Terminalにカーソルを合わせた上でキーボードのCtrlキーを押しながら”c”キーを押します。
次に、”~/CSI-Camera”に留まったままで下記ソースを実行すると目と顔を四角で囲みます。カメラを使ったリアルタイムの画像認識です。
| $ python face_detect.py |
顔の特徴点をとらえる上記”face_detect”を動作させた結果が下図になります。
これを応用することで、COVID-19以降設置が広がったサーモカメラにも活用できそうです。

imagenet-cameraでリアルタイム推論

画面左上のファイルアイコン(ファイルマネジャー)を開き、”Home”にある”jetson-inference”を開きます。続けて、”build”⇒”aarch64″⇒”bin”と順番にフォルダを開き、そのbinフォルダの適当な位置で右クリックをして、ターミナルで開く(Openin Terminal)を選択します。
開いたTerminalで下記を実行します。
| $ ./imagenet-camera –network=googlenet |
プログラムが走り出し、検出している物が何であるのかの推論を表示します。

detectnet-cameraでリアルタイム推論

”detectnet-camera”は、カメラ画像からリアルタイムに推論を行います。
画像の中から対象物を選び出し、推論します。
物体をしっかりと検出して四角で囲んでくれるのでわかりやすいです。
| $ ./detectnet-camera |
プログラムが走り出し、検出している物が何であるのかの推論を表示します。
プログラム動作中の画面キャプチャを以下に示します。
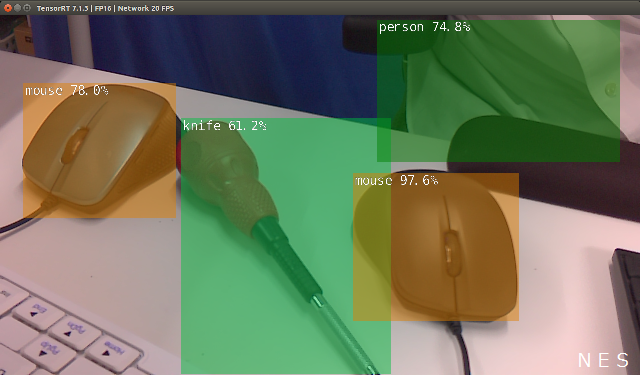
下記のように入力するとカメラとディスプレイの解像度を定義することができます。
| $ ./detectnet-camera –width=480 –height=270 |
segnet-cameraでリアルタイム画像セグメンテーション
”segnet-camera”は、カメラ画像からリアルタイムに画像セグメンテーションを行います。
| $ ./segnet-camera |
保存されている画像を指定してセグメンテーションすることもできます。
| $ ./segnet-console ./images/banana_0.jpg output_banan.jpg |
参考・引用
MONOist: Jetson Nanoで組み込みAIを試す (3) 「Jetson Nano」のCUDAコアで“Hello AI World”を動作させてみる
MONOist: Jetson Nanoで組み込みAIを試す(4) 「Jetson Nano」にUSBカメラをつなげてにゃんこを認識させる
Tora & Mamma: Jetson Nano 買ったので darknet で Nightmare と YOLO を動かすまで
Qiita: Jetson Nano関係のTIPSまとめ, @karaage0703
teratail: カメラ画像をJetson nanoで表示させたい
JetsonHacks: Jetson Nano + Raspberry Pi Camera
MONOist: Jetson Nanoで組み込みAIを試す
猫屋敷工房: NVIDIA Jetson Nanoのサンプルアプリを動かしてみよう、Hello AI World、Two Days to aDemo